

Limpeza de dados em ciência de dados

Nesta série de postagens de blog sobre ciência de dados, já falamos sobre de onde extrair dados e como explorar esses dados usando o pandas, mas embora esses dados sejam excelentes para o aprendizado, não são semelhantes àquilo que chamaremos de “dados do mundo real“. Dados para aprendizado costumam já ter sido limpos e submetidos a uma curadoria para permitirem que você aprenda rapidamente, sem precisar se aventurar no mundo da limpeza de dados, mas dados do mundo real têm problemas e são desordenados. Dados do mundo real precisam ser limpos antes de poderem nos dar insights úteis. Este é o assunto desta postagem de blog.
Problemas com dados podem se originar do comportamento dos próprios dados, da maneira como eles foram reunidos ou até da maneira como eles foram introduzidos. Podem acontecer erros e descuidos em todas as etapas da jornada.
Aqui estamos falando especificamente da limpeza de dados e não da transformação de dados. A limpeza de dados garante que as conclusões às quais você chegar a partir dos seus dados possam ser generalizadas para a população que você definir. Já a transformação de dados envolve tarefas como converter o formato dos dados, normalizá-los e agregá-los.
Por que a limpeza de dados é importante?
A primeira coisa que precisamos entender a respeito de conjuntos de dados é o que eles representam. A maioria dos conjuntos de dados é uma amostra que representa uma população mais ampla. Ao trabalhar com essa amostra, você poderá extrapolar (ou generalizar) os seus achados para essa população. Por exemplo, usamos um conjunto de dados nas duas postagens anteriores deste blog. Em linhas gerais, aquele conjunto de dados é a respeito de vendas de casas, mas ele só cobre uma área geográfica pequena, um período limitado de tempo e não todas as casas em potencial naquela área e período. Ele é uma amostra de uma população maior.
Seus dados precisam ser uma amostra representativa da população mais ampla — por exemplo, todas as vendas de casas naquela área durante um determinado período. Para garantir que nossos dados sejam uma amostra representativa da população mais ampla, precisamos primeiro definir os limites da nossa população.
Como você pode imaginar, geralmente não é prático trabalhar com a população inteira, exceto talvez no caso de dados de censos. Então, você precisa decidir quais são os seus limites. Esses limites podem ser geográficos, demográficos, baseados no tempo ou em ações (tais como ações transacionais), ou específicos de determinados setores da economia. Há inúmeras maneiras de definir a sua população, mas para poder generalizar os seus dados de forma confiável, isso é algo que você precisa fazer antes de limpar os seus dados.
Em resumo, se você estiver planejando usar os seus dados para qualquer tipo de análise ou aprendizado de máquina, precisará de algum tempo para limpar os dados e assim garantir que você possa confiar nos seus insights e generalizá-los para o mundo real. Limpar os seus dados resulta em análises mais precisas e, no que diz respeito ao aprendizado de máquina, também em melhorias de desempenho.
Sem limpar os seus dados, você corre o risco de ter problemas, como não conseguir generalizar o seu aprendizado à população mais ampla de forma confiável, estatísticas imprecisas de resumo e visualizações incorretas. Se você estiver usando os seus dados para treinar modelos de aprendizado de máquina, isso também pode levar a erros e a previsões imprecisas.
Experimente o PyCharm Professional gratuitamente
Exemplos de limpeza de dados
Vamos dar uma olhada em cinco tarefas que você pode usar para limpar os seus dados. Esta não é uma lista completa, mas é um bom lugar para começar quando você obtiver alguns dados do mundo real.
Desduplicação de dados
A duplicação é um problema, porque pode distorcer os seus dados. Imagine que você esteja traçando um histograma, no qual você esteja usando a frequência dos preços de venda. Se houver duplicações de um mesmo valor, você acabará obtendo um histograma com um padrão impreciso, baseado em preços duplicados.
Incidentalmente, quando dizemos que a duplicação é um problema em conjuntos de dados, estamos falando da duplicação de linhas inteiras, cada uma delas referente a uma única observação. Haverá valores duplicados nas colunas e isso é esperado. Estamos falando apenas de observações duplicadas.
Felizmente para nós, há um método do pandas que podemos usar para nos ajudar a detectar se há algum dado duplicado. Se precisarmos de um lembrete, podemos usar o chat do JetBrains AI, com um prompt como este:
Code to identify duplicate rows
E este é o código resultante:
duplicate_rows = df[df.duplicated()] duplicate_rows
Este código presume que a sua dataframe tem o nome de df. Se ela tiver outro nome, certifique-se de mudá-lo.
Não há dados duplicados no conjunto de dados da Ames Housing, que estivemos usando, mas se você tiver vontade de experimentar o método do pandas descrito acima, dê uma olhada no banco de dados do CITES Wildlife Trade e veja se encontra dados duplicados usando esse método.
Depois de identificar duplicações no seu conjunto de dados, você precisa removê-las, para evitar distorcer os seus resultados. Novamente, você pode obter o código para isso através do JetBrains AI, com um prompt como este:
Code to drop duplicates from my dataframe
O código resultante elimina as duplicações, reinicializa o índice da sua dataframe e depois mostra-a como uma nova dataframe chamada df_cleaned:
df_cleaned = df.drop_duplicates() df_cleaned.reset_index(drop=True, inplace=True) df_cleaned
Há outras funções do pandas que você pode usar para um gerenciamento avançado de dados duplicados, mas isto basta para você começar a desduplicar o seu conjunto de dados.
Como lidar com valores implausíveis
Podem ocorrer valores implausíveis quando os dados forem informados incorretamente ou algo der errado no processo de reuni-los. No caso do nosso conjunto de dados da Ames Housing, um valor implausível poderia ser um preço de venda negativo ou um valor numérico em “estilo do telhado”.
Identificar valores implausíveis no seu conjunto de dados depende de uma abordagem ampla, que inclui dar uma olhada nas suas estatísticas de resumo, verificar as regras de validação de cada coluna, definidas pelo coletor dos dados, e observar quaisquer pontos de dados que caiam fora dessa validação, além de usar visualizações para identificar padrões ou qualquer coisa que pareça anômala.
É melhor você cuidar dos valores implausíveis, pois eles podem acrescentar ruído e causar problemas com a sua análise. Porém, a forma de lidar com eles é um tanto aberta a interpretações. Se não houver muitos valores implausíveis para o tamanho do seu conjunto de dados, talvez você queira remover os registros que os contiverem. Por exemplo, se você tiver identificado um valor implausível na linha 214 do seu conjunto de dados, poderá usar a função “drop” do pandas para remover essa linha.
Mais uma vez, o JetBrains AI pode gerar o código necessário, com um prompt como este:
Code that drops index 214 from #df_cleaned
Observe que em notebooks do Jupyter no PyCharm, é possível usar o sinal “#” como prefixo para indicar ao JetBrains AI Assistant que está sendo fornecido contexto adicional — neste caso, que a dataframe tem o nome de df_cleaned.
O código resultante removerá aquele dado observado da sua dataframe, reinicializará o índice e o mostrará:
df_cleaned = df_cleaned.drop(index=214) df_cleaned.reset_index(drop=True, inplace=True) df_cleaned
Outra estratégia popular para lidar com valores implausíveis é imputá-los, ou seja, substituí-los por um valor diferente e plausível, com base em uma estratégia definida. Uma das estratégias mais comuns é usar o valor da mediana no lugar do valor implausível. Como a mediana não é afetada por valores atípicos, ela costuma ser escolhida para isso pelos cientistas de dados, mas da mesma forma, o valor da média ou da moda dos seus dados pode ser mais apropriada em algumas situações.
Como alternativa, se você tiver conhecimento específico sobre aquele conjunto de dados e a forma como os dados foram obtidos, poderá substituir o valor implausível por outro mais significativo. Se você estiver envolvido no processo de coleta de dados ou souber como ele foi feito, talvez esta opção seja indicada para você.
A escolha de como lidar com valores implausíveis dependerá da prevalência deles no seu conjunto de dados, de como os dados foram coletados e de como você pretende definir a sua população, além de outros fatores, como o seu conhecimento específico.
Formatação dos dados
É comum observar problemas de formatação através das suas estatísticas de resumo ou de visualizações iniciais que você faça para ter uma ideia da forma dos seus dados. Valores numéricos não definidos todos com o mesmo número de casas decimais ou variações de ortografia, como “primeiro” e “1º”, são exemplos de formatação inconsistente. Dados formatados incorretamente também podem ter implicações para o uso de memória pelos seus dados.
Após identificar problemas de formatação no seu conjunto de dados, é preciso padronizar os valores. Dependendo do problema que estiver havendo, normalmente isso envolve definir o seu próprio padrão e aplicar as mudanças. Mais uma vez, a biblioteca pandas tem algumas funções úteis para isso, como round. Se você quiser arredondar a coluna “SalePrice” para duas casas decimais, pode pedir o código ao JetBrains AI:
Code to round #SalePrice to two decimal places
O código resultante fará o arredondamento e imprimirá as primeiras 10 linhas para você verificá-las:
df_cleaned['SalePrice'] = df_cleaned['SalePrice].round(2) df_cleaned.head()
Outro exemplo: talvez haja casos de ortografia inconsistente — por exemplo, valores “1Story” e “OneStory” na coluna “HouseStyle” e você está certo de que eles significam a mesma coisa. Você pode usar este prompt para obter código para isso:
Code to change all instances of #OneStory to #1Story in #HouseStyle
O código resultante faz exatamente isso e substitui todas as ocorrências de “OneStory” por “1Story”:
df_cleaned[HouseStyle'] = df_cleaned['HouseStyle'].replace('OneStory', '1Story')
Tratamento de valores atípicos
Valores atípicos são muito comuns em conjuntos de dados, mas a forma de tratá-los — se você for tratá-los — depende muito do contexto. Uma das maneiras mais fáceis de identificar valores atípicos é através de um diagrama de caixas, que usa as bibliotecas seaborn e matplotlib. Se você precisar de uma revisão rápida, já discuti diagramas de caixas em uma postagem anterior, sobre como explorar dados com o pandas.
Para este diagrama de caixas, vamos usar “SalePrice” no nosso conjunto de dados de imóveis residenciais da Ames. Novamente, vamos usar o JetBrains AI para gerar o código, com um prompt como este:
Code to create a box plot of #SalePrice
E este é o código resultante, que precisaremos executar:
import seaborn as sns
import matplotlib.pyplot as plt
# Create a box plot for SalePrice
plt.figure(figsize=(10, 6))
sns.boxplot(x=df_cleaned['SalePrice'])
plt.title('Box Plot of SalePrice')
plt.xlabel('SalePrice')
plt.show()
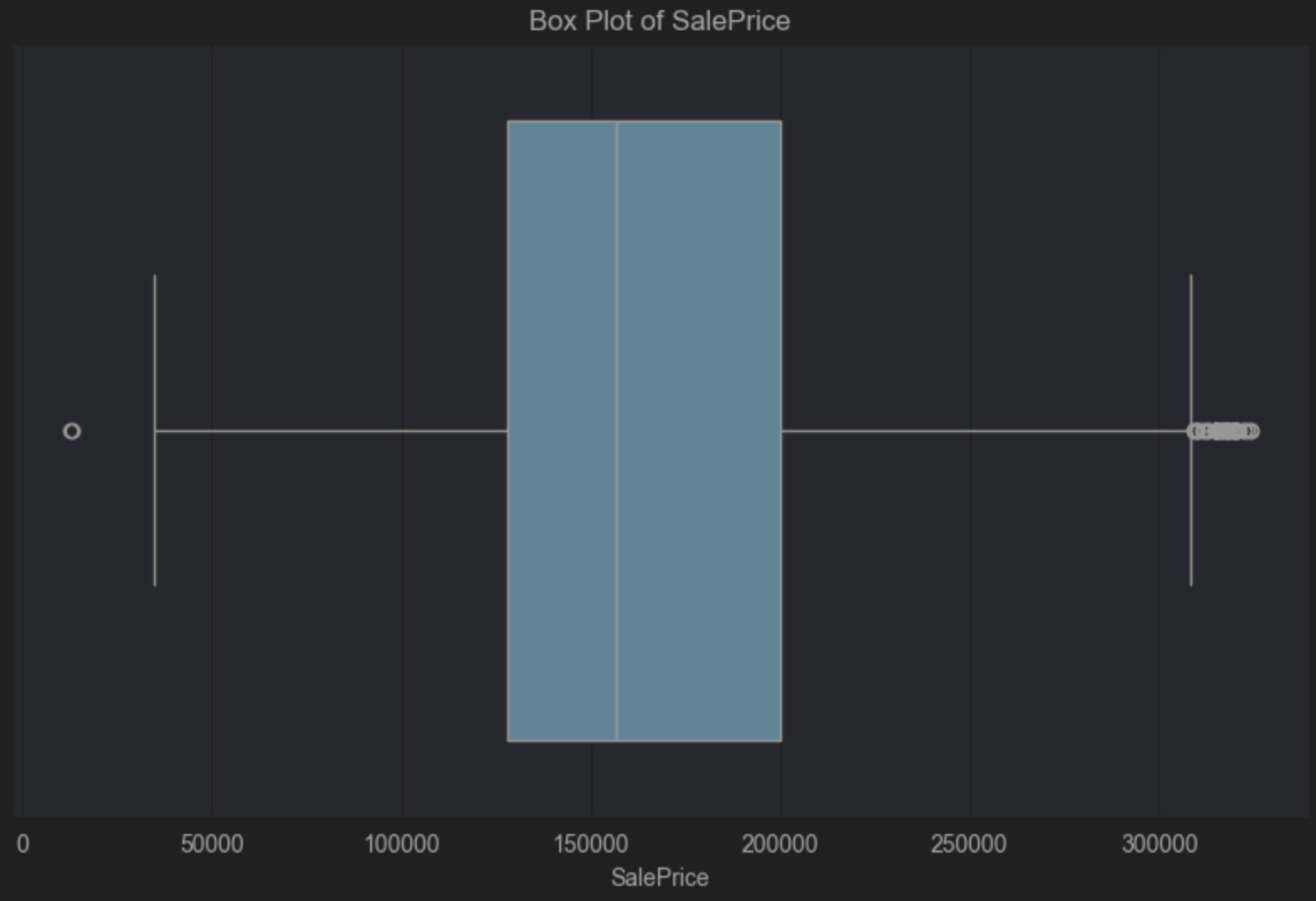
O diagrama de caixas nos diz que há uma assimetria positiva, porque a linha vertical da mediana, dentro da caixa azul, está à esquerda do centro. Uma assimetria positiva diz que há mais preços de casas na parte mais barata da escala, o que não surpreende. O diagrama de caixas também nos diz visualmente que há muitos valores atípicos no lado direito. É um pequeno número de casas muito mais caras que a mediana dos preços.

Talvez você queira aceitar esses valores atípicos, pois é razoável esperar um pequeno número de casas com preços maiores que os da maioria. Porém, isso depende da população para a qual você quer poder generalizar os dados e das conclusões às quais você deseja chegar a partir dos seus dados. Colocando limites claros em torno do que faz ou não faz parte da sua população, você poderá decidir de forma informada se os valores atípicos dos seus dados serão ou não um problema.
Por exemplo, se a sua população consistir de pessoas que não irão comprar mansões caras, talvez você possa eliminar esses valores atípicos. Por outro lado, se os seus dados demográficos incluírem pessoas das quais se pode esperar com razoável certeza que comprem casas caras, talvez você queira manter esses valores, pois eles serão relevantes para a sua população.
Falei aqui dos diagramas de caixas como uma maneira de identificar valores atípicos, mas há outras opções, como gráficos de dispersão e histogramas, que podem rapidamente lhe mostrar se há valores atípicos nos seus dados, para que você possa tomar uma decisão informada sobre se precisa fazer algo a respeito deles.
Geralmente, o tratamento de valores atípicos cai em duas categorias — excluí-los ou usar estatísticas de resumo menos propensas a eles. No primeiro caso, precisamos saber exatamente em que linhas estão esses valores.
Até agora, vimos discutindo apenas como identificar valores atípicos visualmente, mas há maneiras diferentes de determinar quais dados observados são atípicos ou não. Uma abordagem comum é usar um método chamado escore Z modificado. Antes de olharmos como e por que o escore Z é modificado, vamos defini-lo como:
Escore Z = (valor do ponto de dados – média) / desvio-padrão
A razão pela qual modificamos o escore Z para detectarmos valores atípicos é que tanto a média quanto o desvio-padrão são propensos a serem influenciados por valores atípicos, devido à forma como são calculados. O escore Z modificado é definido como:
Escore Z modificado = (valor do ponto de dados – mediana) / mediana dos desvios absolutos
Como aprendemos ao falarmos das estatísticas de resumo, a mediana não é afetada por valores atípicos. A mediana dos desvios absolutos é o valor mediano dos desvios absolutos da mediana do conjunto de dados. Por exemplo, se o seu conjunto de dados contiver estes valores:
1, 2, 2, 2, 3, 3, 3, 5,9
então a sua mediana é 3, pois este é o valor na metade do conjunto de dados. Os desvios do seu valor de 3 na mediana são os seguintes, na ordem apresentada acima:
2, 1, 1, 1, 0, 0, 0, 2, 5
Ao ordenarmos estes valores em ordem crescente, obtemos:
0, 0, 0, 1, 1, 1, 2, 2, 5
Isso significa que neste exemplo, a mediana dos desvios absolutos é 1.
Como calcular o escore Z modificado do nosso conjunto de dados para o preço de venda (SalePrice)? Vamos dar o seguinte prompt no JetBrains AI:
Given:
Modified Z-score = (data point value – median) / median absolute deviation
Calculate the Modified Z-score for #SalePrice
Isso resulta no seguinte código:
import pandas as pd from scipy.stats import median_abs_deviation # Assuming 'data' is your DataFrame and it contains the 'SalePrice' column # Calculate the median for the SalePrice column median_sale_price = data['SalePrice'].median() # Calculate the Median Absolute Deviation (MAD) for the SalePrice column mad_sale_price = median_abs_deviation(data['SalePrice'], scale='normal') # Calculate the Modified Z-scores for the SalePrice column data['Modified_Z_Score'] = (data['SalePrice'] - median_sale_price) / mad_sale_price # Display the first few rows with the Modified Z-scores print(data[['SalePrice', 'Modified_Z_Score']].head())
Ao instalarmos os pacotes necessários e executarmos este código, podemos ver que já fizemos parte do trabalho, mas agora precisamos decidir o que seria um valor atípico de SalePrice, com base no escore Z modificado. Aqui, o consenso geral é de que qualquer valor ≥ 3 ou ≤ −3 é atípico, mas vale observar que, como a maioria das decisões estatísticas, esta definição pode e deve ser ajustada ao seu conjunto de dados. <=-3 however, it’s worth noting that like most statistical decisions, it can and should be tailored to your dataset.
Vamos passar outro prompt para o JetBrains AI, para podermos refinar melhor nossa saída:
Just list those that have a #Modified_Z_Score of 3 or above or -3 or below
Vou substituir este trecho de código pelas linhas relevantes acima:
# Filter the rows where the Modified Z-score is 3 or above, or -3 or below outliers = data[(data['Modified_Z_Score'] >= 3) | (data['Modified_Z_Score'] <= -3)] # Print all the filtered rows, showing their index and SalePrice outliers = (outliers[['SalePrice', 'Modified_Z_Score']]) outliers
Modifiquei este código para salvar os valores atípicos em uma nova dataframe chamada “outliers” e imprimi-los para eu poder visualizá-los.
Nossa próxima etapa será remover esses valores atípicos da nossa dataframe. Mais uma vez, podemos usar o JetBrains AI para gerar o código, com um prompt como este:
Create a new dataframe without the outliers
data_without_outliers = data.drop(index=outliers.index) # Display the new DataFrame without outliers print(data_without_outliers)
Nossa nova dataframe, data_without_outliers, exclui os valores nos quais a variável SalePrice é considerada atípíca.
Podemos atualizar o código do nosso diagrama de caixas para considerar a nova dataframe. O diagrama ainda mostra uma assimetria positiva, como esperado, mas os valores considerados atípicos foram removidos:
import seaborn as sns
import matplotlib.pyplot as plt
# Create a box plot for SalePrice
plt.figure(figsize=(10, 6))
sns.boxplot(x=data_without_outliers['SalePrice'])
plt.title('Box Plot of SalePrice')
plt.xlabel('SalePrice')
plt.show()
Antes de terminarmos, vamos dar uma olhada em que porcentagem dos dados observados foi removida da nossa dataframe, pois nós os consideramos valores atípicos com base em “SalePrice”.
Podemos usar um prompt como este:
Calculate the percentage of observations removed between #data and #data_without_outliers
# Calculate the number of observations in the original and filtered DataFrames
original_count = len(data)
filtered_count = len(data_without_outliers)
# Calculate the number of removed observations
removed_count = original_count - filtered_count
# Calculate the percentage of observations removed
percentage_removed = (removed_count / original_count) * 100
# Display the percentage
print(f"Percentage of observations removed: {percentage_removed:.2f}%")
O PyCharm diz que 5,67% dos dados observados foram removidos.
Como já mencionei antes, se você for manter os valores atípicos, considere usar valores de resumo menos propensos a serem afetados por eles, como a mediana e o intervalo entre quartis. Talvez você queira usar essas medidas para formar as suas conclusões ao trabalhar com conjuntos de dados que você sabe conterem valores atípicos, não removidos porque eles são relevantes para a população que você definiu e as conclusões que você pretende obter.
Valores faltando
A maneira mais fácil de identificar valores faltando no seu conjunto de dados é através das suas estatísticas de resumo. Como lembrete, na sua dataframe, clique em Show Column Statistics no lado direito e depois selecione Compact. Os valores que estiverem faltando nas colunas serão mostrados em vermelho, como você pode ver no caso de “Lot Frontage” no conjunto de dados de imóveis residenciais da Ames:
Há três tipos de faltas de dados a serem consideradas:
- Dados faltando de forma completamente aleatória
- Dados faltando de forma aleatória
- Dados faltando de forma não aleatória
Dados faltando de forma completamente aleatória
Dados faltando de forma completamente aleatória significam que isso ocorreu inteiramente por acaso e que o fato de eles estarem faltando não tem relação com as outras variáveis do conjunto de dados. Isso pode ocorrer quando alguém se esquece de responder a uma pergunta da pesquisa, por exemplo.
Dados faltando de forma completamente aleatória são raros, mas também estão entre os mais fáceis de se lidar. Se você tiver um número relativamente pequeno de dados observados faltando de forma completamente aleatória, a abordagem mais comum é excluir essas observações, porque isso não afetará a integridade do seu conjunto de dados e, por conseguinte, as conclusões que você espera obter.
Dados faltando de forma aleatória
Dados faltando de forma aleatória não têm um padrão aparente, mas têm um padrão subjacente que podemos explicar através das outras variáveis que medimos. Por exemplo, alguém não respondeu uma pergunta da pesquisa por causa da forma como os dados foram coletados.
Mais uma vez no nosso conjunto de dados de imóveis residenciais da Ames, considere que talvez a variável “Lot Frontage” esteja faltando mais vezes para casas vendidas por determinadas imobiliárias. Nesse caso, essa falta pode ser por causa de práticas inconsistentes de entrada de dados por algumas imobiliárias. Se isso for verdade, a falta dos dados de “Lot Frontage” estará relacionada à forma como a imobiliária que vendeu a propriedade coletou os dados. Isso é uma característica observada, não da própria variável “Lot Frontage”.
Quando houver dados faltando de forma aleatória, você irá querer entender por que isso aconteceu, o que costuma envolver uma investigação de como os dados foram coletados. Depois de entender por que os dados estão faltando, você poderá decidir o que fazer. Uma das abordagens mais comuns para lidar com dados faltando de forma aleatória é imputar os valores. Já falamos disso a respeito de valores implausíveis, mas essa também é uma estratégia válida para dados faltando. Há várias opções que você pode escolher, com base na população que você definiu e nas conclusões que você deseja tirar, incluindo usar variáveis correlatas, como, neste exemplo, o tamanho da casa, o ano de construção e o preço de venda. Se você compreender o padrão por trás dos dados faltando, geralmente poderá usar informações de contexto para imputar os valores, o que garantirá que as relações entre os dados do seu conjunto sejam preservadas.
Dados faltando de forma não aleatória
Por fim, dados faltando de forma não aleatória ocorrem quando a probabilidade de eles faltarem está relacionada a dados não observados. Isso significa que a falta dos dados depende dos dados não observados.
Vamos voltar uma última vez ao nosso conjunto de dados de imóveis residenciais da Ames e ao fato de que estão faltando dados de “Lot Frontage”. Uma hipótese para os dados estarem faltando de forma não aleatória é os vendedores decidirem deliberadamente não informar “Lot Frontage”, por considerarem que a frente do lote é pequena demais e que isso poderia reduzir o preço de venda da casa. Se a probabilidade de faltarem dados de “Lot Frontage” depender do próprio comprimento da frente do lote (que não foi observado), frentes menores terão uma probabilidade menor de serem informadas, o que significa que a falta desse dado estará diretamente relacionada ao valor dele.
Visualização da falta de dados
Sempre que faltarem dados, você precisará determinar se há algum padrão. Se houver um padrão, então haverá um problema que você provavelmente terá de resolver antes de poder generalizar os seus dados.
Uma das maneiras mais fáceis de procurar padrões é através de visualizações em mapa de calor. Antes de entrarmos no código, vamos excluir as variáveis que não têm dados faltando. Para obtermos esse código, podemos usar o seguinte prompt no JetBrains AI:
Code to create a new dataframe that contains only columns with missingness
Aqui está nosso código:
# Identify columns with any missing values columns_with_missing = data.columns[data.isnull().any()] # Create a new DataFrame with only columns that have missing values data_with_missingness = data[columns_with_missing] # Display the new DataFrame print(data_with_missingness)
Antes de executar este código, altere a última linha, para podermos aproveitar o ótimo layout de dataframes do PyCharm:
data_with_missingness
Agora é o momento de criarmos um mapa de calor. Mais uma vez, daremos ao JetBrains AI um código como este:
Create a heatmap of #data_with_missingness that is transposed
E este é o código resultante:
import seaborn as sns
import matplotlib.pyplot as plt
# Transpose the data_with_missingness DataFrame
transposed_data = data_with_missingness.T
# Create a heatmap to visualize missingness
plt.figure(figsize=(12, 8))
sns.heatmap(transposed_data.isnull(), cbar=False, yticklabels=True)
plt.title('Missing Data Heatmap (Transposed)')
plt.xlabel('Instances')
plt.ylabel('Features')
plt.tight_layout()
plt.show()
Observe que removi “cmap=’viridis'” dos argumentos do mapa de calor, pois eu o acho difícil de visualizar.

Este mapa de calor sugere que pode haver um padrão de falta, porque as mesmas variáveis estão faltando em diversas linhas. Em um grupo, podemos ver que “Bsmt Qual”, “Bsmt Cond”, “Bsmt Exposure”, “BsmtFin Type 1” e “Bsmt Fin Type 2” estão todas faltando das mesmas observações. Em outro grupo, podemos ver que “Garage Type”, “Garage Yr Bit”, “Garage Finish”, “Garage Qual” e “Garage Cond” estão todos faltando nos mesmos dados observados.
Todas essas variáveis referem-se a porões e garagens, mas há outras variáveis também referentes a eles que não estão faltando. Uma possível explicação é que, ao coletar os dados, perguntas diferentes sobre garagens e porões podem ter sido feitas em imobiliárias diferentes e talvez nem todas elas tenham sido registradas com tantos detalhes quanto no conjunto de dados. Essas situações são comuns com dados que você não coletou pessoalmente. Se você precisar saber mais sobre dados faltando no seu conjunto de dados, poderá explorar a forma como esses dados foram coletados.
Melhores práticas em limpeza de dados
Como já mencionei, definir a sua população tem alta prioridade na lista das melhores práticas em limpeza de dados. Saiba o que você quer alcançar e como você deseja generalizar os seus dados antes de começar a limpá-los.
Você precisa garantir que todos os seus métodos sejam reproduzíveis, porque isso se correlaciona a dados limpos. Situações não reproduzíveis podem ter um impacto significativo mais adiante. Por isso, recomendo manter os seus notebooks do Jupyter organizados e em sequência, além de aproveitar os recursos do Markdown para documentar a sua tomada de decisões em cada etapa, especialmente na limpeza.
Ao limpar dados, você deve trabalhar de forma incremental, modificando a dataframe e não o arquivo em CSV ou banco de dados original e garantindo que você faça tudo com código reproduzível e bem documentado.
Resumo
A limpeza de dados é um assunto extenso e pode ter muitos desafios. Quanto maior for o conjunto de dados, mais desafiador será o processo de limpeza. Você precisará ter em mente a sua população para poder generalizar mais amplamente as suas conclusões, equilibrando compromissos entre remover e imputar valores faltando, por um lado, e compreender por que esses dados estão faltando, por outro.
Pense em si mesmo como a voz dos dados. Você conhece a jornada pela qual os dados passaram e sabe como manteve a integridade dos dados em todas as etapas. Você é a pessoa mais indicada para documentar essa jornada e compartilhá-la com outras pessoas.
Experimente o PyCharm Professional gratuitamente
Artigo original em inglês por:

Subscribe to PyCharm Blog updates





