

Python で学ぶ時系列の異常検知


重大な問題や隠れた機会を示している可能性のある異常なデータパターンを発見するにはどうすればいいのでしょうか? 通常の値から大幅に逸脱しているデータを発見するには、異常検知が役立ちます。 ある期間に収集されたデータで構成される時系列データには、トレンドや季節性のパターンが往々にして含まれています。 時系列データ内の異常はこれらのパターンが変動したときに発生するため、異常検知は販売、金融、製造、ヘルスケアなどの業界で重宝されるツールとなっています。
時系列データには季節性やトレンドといった固有の特徴があるため、異常を効果的に検出するには特別な手法が必要です。 このブログ記事では、STL 分解や LSTM 予測などの一般的な時系列の異常検知手法と、作業を開始するのに役立つ詳細なコード例を見ていきます。
ビジネスにおける時系列異常検知
時系列データは多くのビジネスやサービスに欠かせないものです。 多くのビジネスではタイムスタンプ付きの時系列データを記録し、それによって一定期間内の変化を分析してデータを比較できるようにしています。 時系列は、データが季節性の特徴を示す前年比比較のように特定期間における特定の数量を比較する際に役立ちます。
売上の監視
季節性のある時系列データの代表的な例の 1 つには、売上データがあります。 売上の多くは毎年の祝祭日や季節による影響を受けるため、季節性を考慮せずに売上データに関する結論を導くのは困難です。 そのため、売上データを分析して異常を発見するには、STL 分解という手法が用いられるのが一般的です。これについてはこのブログ記事の後半で詳しく説明します。
金融
時系列データの一般的な例には、取引や株価といった金融データがあります。 金融業界では、このデータを分析して異常を検知するのが一般的です。 たとえば、時系列予測モデルを自動売買に使用することができます。 このブログ記事の後半では、時系列予測を使用して株式データの異常を発見しています。
製造
時系列の異常検知は、生産ラインでの欠陥の監視にも使用されています。 機械は監視されており、時系列データを提供しているのが一般的です。 潜在的な障害を管理者に通知できることは不可欠であり、異常検知は重要な役割を果たしています。
医療とヘルスケア
医療とヘルスケアの分野では、人のバイタルサインを監視して異常を検知できます。 これは医療研究では十分に重要なことですが、診断では不可欠なことです。 入院患者のバイタルサインに異常があるのに応急措置が取られない場合、致命的な結果になりかねません。
時系列異常検知に特殊な手法を用いることが重要な理由
時系列データは、他の種類のデータと同様に扱えないことがある点で特別です。 たとえば、時系列データに対してトレーニング/テスト分割を適用する場合、データは時間的に連続して関係しているため、シャッフルすることはできません。 時系列データをディープラーニングモデルに適用する場合にも同じことが言えます。 連続的な関係性を考慮するには回帰型ニューラルネットワーク(RNN)が一般的に使用されます。トレーニングデータは時間枠として入力され、その中でイベントの順序が保持されます。
時系列データが特殊なのは、無視できない季節性とトレンドが含まれていることが多いからでもあります。 この季節性は、一般的には 24 時間、7 日、または 12 か月などの周期で現れます。 以下の例から分かるように、異常を判断できるのは季節性とトレンドが考慮された後だけです。
時系列の異常検知に使用される手法
時系列データは特殊であるため、その中の異常を検知するための特別な手法があります。 データの種類にもよりますが、時系列には前の異常検知に関するブログ記事で述べたいくつかの手法とアルゴリズムを使用することができます。 ただし、それらの手法による異常検知は、時系列データ用に特別に設計された手法ほど信頼できるものではない可能性があります。 場合によっては検知手法を組み合わせて使用し、検知結果を再確認して偽陽性や偽陰性の誤検知を回避することができます。
STL 分解
季節性が含まれる時系列を使用する最も一般的な方法の 1 つに、LOESS(局所推定散布図平滑化)を使用した季節性とトレンドの分解、つまり STL 分解があります。 この手法では、時系列が季節性の推定値(指定された期間またはアルゴリズムを使用して決定された期間)、トレンド(推定)、および残差(データのノイズ)を使用して分解されます。 statsmodels ライブラリは、STL 分解ツールを提供する Python ライブラリです。

残差がある特定のしきい値を超えると異常が検知されます。
養蜂箱データでの STL 分解の使用
前のブログ記事では、OneClassSVM および IsolationForest メソッドを使った養蜂箱の異常検知について探りました。
このチュートリアルでは、statsmodels ライブラリが提供する STL クラスを使用し、養蜂箱データを時系列として分析します。 まずは、こちらの requirements.txt ファイルを使用して環境をセットアップしましょう。
1. ライブラリをインストールする
これまでは Scikit-learn が提供するモデルのみを使用してきたため、PyPI から statsmodels をインストールする必要があります。 PyCharm なら簡単に行えます。
Python Package(Python パッケージ)ウィンドウに移動し(IDE の左下にあるアイコンを選択)、検索ボックスに「statsmodels」と入力します。

パッケージに関するすべての情報が右側に表示されます。 Install package(パッケージのインストール)をクリックしてインストールしてください。
2. Jupyter ノートブックを作成する
データセットをさらに調査するため、Jupyter ノートブック を作成しましょう。それにより、PyCharm の Jupyter ノートブック環境が提供するツールのメリットを活用できます。

pandas をインポートして、.csv ファイルを読み込みます。
import pandas as pd
df = pd.read_csv('../data/Hive17.csv', sep=";")
df = df.dropna()
df

3. データをグラフ形式で調べる
データをグラフ形式で調べられるようになりました。 ここでは、養蜂箱 17 番のある期間の温度を見てみたいと思います。 DataFrame インスペクターの Chart view(チャートビュー)をクリックし、系列設定で T17 を y 軸に選択します。

時系列で表示されているように、温度には多数の上下変動があります。 これは昼夜のサイクルによる定期的な振る舞いを示していると思われるため、温度には 24 時間の周期があると見なしてよいでしょう。
次に、温度が経時的に低下しているトレンドが見られます。 DateTime 列を確認すると、日付の範囲が 8 月から 11 月になっているのがわかります。 Kaggle のデータセットページにはトルコでデータが収集されたとあるため、温度が経時的に低下しているという観測は夏から秋への変化によるものだと説明できます。
4. 時系列の分解
時系列を理解して異常を検知するため、statsmodels から STL クラスをインポートしてそれを温度データに適合させてから STL 分解を行います。
from statsmodels.tsa.seasonal import STL stl = STL(df["T17"], period=24, robust=True) result = stl.fit()
分解を行う期間を指定する必要があります。 前述のように、24 時間の周期があると仮定するのが無難です。
ドキュメントによると、STL は時系列をトレンド、季節性、および残差の 3 つの要素に分解します。 分解された結果を分かりやすくするため、組み込みの plot メソッドを使用しましょう。
result.plot()

Trend(トレンド)と Season(季節)プロットが上記の仮定と一致しているのが分かります。 ただし、関心があるのは一番下にある残差のプロットです。これは、トレンドと季節性の変化が含まれない本来の系列です。 残差内の極度に高い値や低い値は異常を示しています。
5. 異常のしきい値
次に、残差のどの値を異常と見なすかを判断しましょう。 これを行うため、残差のヒストグラムを確認します。
result.resid.plot.hist()

これは、5 より上と -5 より下に長い裾を持つ 0 を中心とする正規分布であると見なせるため、しきい値を 5 に設定します。
本来の時系列で異常を示すため、以下のようにしてグラフ内のすべての異常を赤くしましょう。
import matplotlib.pyplot as plt
threshold = 5
anomalies_filter = result.resid.apply(lambda x: True if abs(x) > threshold else False)
anomalies = df["T17"][anomalies_filter]
plt.figure(figsize=(14, 8))
plt.scatter(x=anomalies.index, y=anomalies, color="red", label="anomalies")
plt.plot(df.index, df['T17'], color='blue')
plt.title('Temperatures in Hive 17')
plt.xlabel('Hours')
plt.ylabel('Temperature')
plt.legend()
plt.show()

STL 分解を行わない場合、期間とトレンドで構成される時系列内でこれらの異常を発見するのは非常に困難です。
LSTM による予測
時系列データ内の異常を検知する方法には、ディープラーニングの手法を使用して系列に対して時系列予測を行い、データポイントの結果を予測する方法もあります。 予測が実際のデータポイントと大きく異なっている場合、それは異常のあるデータの兆候だと考えられます。
連続的データの予測を実行するのに一般的なディープラーニングアルゴリズムの 1 つに、回帰型ニューラルネットワーク(RNN)の一種である長・短期記憶(LSTM)モデルがあります。 LSTM モデルには入力ゲート、忘却ゲート、および出力ゲートがあり、これらは数値行列です。 これにより、データの次の反復処理に重要な情報が確実に渡されます。

時系列データは連続したデータ(データポイントの順序が連続しているデータ)であり、シャッフルできません。LSTM モデルはある特定の時間の出力を予測するのに効果的なディープラーニングモデルです。 この予測を実際のデータと比較すると、実際のデータが異常かどうかを判断するためのしきい値を設定できます。
株価に対する LSTM 予測の使用
では、新しい Jupyter プロジェクトを開始して、過去 5 年間における Apple の株価の異常を検知してみましょう。 株価データセットは最新のデータを示しています。 このブログ記事に沿って作業を進める場合は、ここで使用しているデータセットをダウンロードしてください。
1. Jupyter プロジェクトを開始する
新規プロジェクトを開始する際には、データサイエンスに最適化された Jupyter プロジェクトの作成を選択できます。 New Project(新規プロジェクト)ウィンドウで Git リポジトリを作成し、どの conda インストールを使用して環境を管理するかを決定します。

プロジェクトを起動すると、サンプルのノートブックが表示されます。 この演習に使用する新しい Jupyter ノートブックを作成してください。
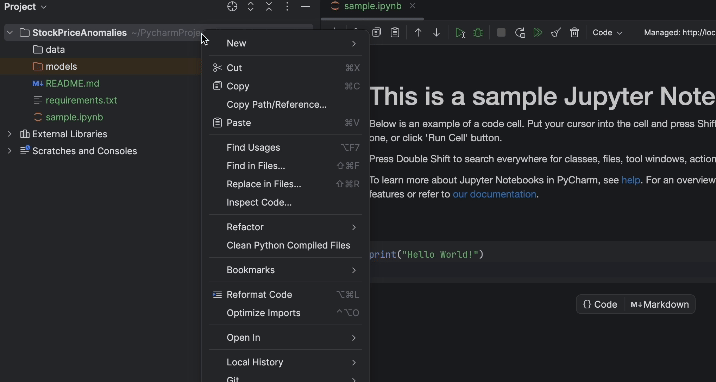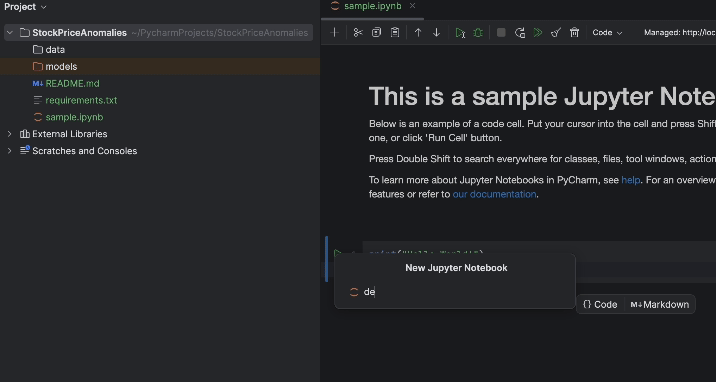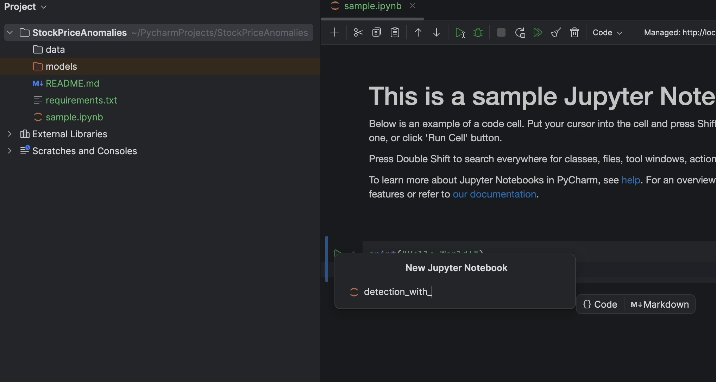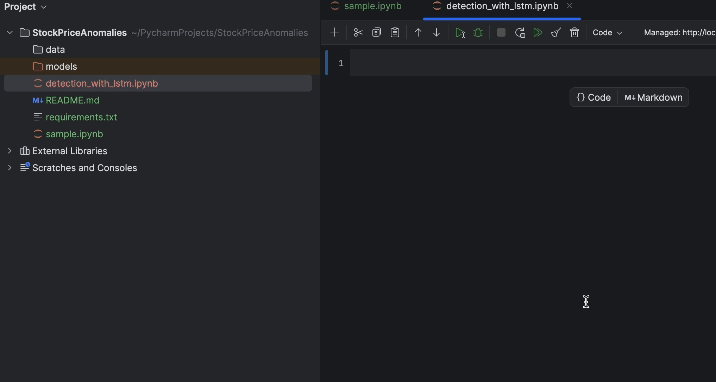
作成したら、requirements.txt をセットアップしましょう。 pandas、matplotlib、および PyPI で「torch」と名付けられている PyTorch が必要です。 PyTorch は conda 環境には含まれていないため、PyCharm からそのパッケージが欠落していると通知されます。 このパッケージをインストールするには、電球アイコンをクリックし、Install all missing packages(すべての欠落パッケージをインストール)を選択してください。

2. データの読み込みと検査
次に、apple_stock_5y.csv データセットを data フォルダーに配置し、pandas DataFrame として読み込んで検査します。
import pandas as pd
df = pd.read_csv('data/apple_stock_5y.csv')
df
対話型テーブルを使用すると、欠損データがないかを簡単に確認できます。

欠損データはありませんが、1 つ問題があります。Close/Last 価格を使用したいのですが、これは数値データ型ではありません。 変換を行い、もう一度データを検索しましょう。
df["Close/Last"] = df["Close/Last"].apply(lambda x: float(x[1:])) df
対話型テーブルを使って価格を検査できるようになりました。 左側のプロットアイコンをクリックすると、プロットが作成されます。 デフォルトでは x 軸に Date、y 軸に Volume が使用されています。 検査するのは Close/Last 価格であるため、右側の歯車アイコンをクリックして設定に移動し、Close/Last を y 軸に選択します。

3. LSTM のトレーニングデータを準備する
LSTM モデルで使用されるトレーニングデータを準備する必要があります。 次の価格を予測するためには、それぞれが時間枠を表す一連のベクトル(特徴量 X)を準備しなければなりません。 次の価格によって別のシーケンス(ターゲット y)が作成されます。 ここでは、この時間枠の大きさを lookback 変数を使用して選択できます。 以下のコードは、シーケンス X と y を作成し、それらを PyTorch テンソルに変換しています。
import torch
lookback = 5
timeseries = df[["Close/Last"]].values.astype('float32')
X, y = [], []
for i in range(len(timeseries)-lookback):
feature = timeseries[i:i+lookback]
target = timeseries[i+1:i+lookback+1]
X.append(feature)
y.append(target)
X = torch.tensor(X)
y = torch.tensor(y)
print(X.shape, y.shape)
一般的には枠が大きいほど入力ベクトルが大きくなるため、モデルも大きくなります。 ただし、枠が大きいほど入力のシーケンスが短くなるため、この lockback 枠の指定ではバランスを取る必要があります。 まずは 5 から始めますが、違いを確認するために他の値も自由に試してみてください。
4. モデルを構築してトレーニングする
モデルをトレーニングする前に、PyTorch の nn モジュールを使用するクラスを作成してモデルを構築できます。 nn モジュールには各種のニューラルネットワークレイヤーなど、複数のビルディングブロックが備わっています。 この演習では単純な LSTM レイヤーを構築し、Linear レイヤーをその後に構築します。
import torch.nn as nn
class StockModel(nn.Module):
def __init__(self):
super().__init__()
self.lstm = nn.LSTM(input_size=1, hidden_size=50, num_layers=1, batch_first=True)
self.linear = nn.Linear(50, 1)
def forward(self, x):
x, _ = self.lstm(x)
x = self.linear(x)
return x
次に、モデルをトレーニングします。 トレーニングする前に、optimizer、予測される y 値と実際の y 値の間の損失を計算するために使用する損失関数、トレーニングデータをフィードするためのデータローダーを作成する必要があります。
import numpy as np import torch.optim as optim import torch.utils.data as data model = StockModel() optimizer = optim.Adam(model.parameters()) loss_fn = nn.MSELoss() loader = data.DataLoader(data.TensorDataset(X, y), shuffle=True, batch_size=8)
データローダーは入力をシャッフルできます。これはすでに時間枠を作成済みであり、 それによって各枠内の連続的な関係性が維持されているためです。
エポックごとにループ処理を行う for ループを使ってトレーニングを行います。 100 エポックごとに損失を出力し、モデルが収束する様子を観察します。
n_epochs = 1000
for epoch in range(n_epochs):
model.train()
for X_batch, y_batch in loader:
y_pred = model(X_batch)
loss = loss_fn(y_pred, y_batch)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 100 != 0:
continue
model.eval()
with torch.no_grad():
y_pred = model(X)
rmse = np.sqrt(loss_fn(y_pred, y))
print(f"Epoch {epoch}: RMSE {rmse:.4f}")
ここでは 1000 エポックから開始していますが、モデルは非常に素早く収束します。 最良の結果を得るため、他のエポック数を自由に試してトレーニングしてみてください。
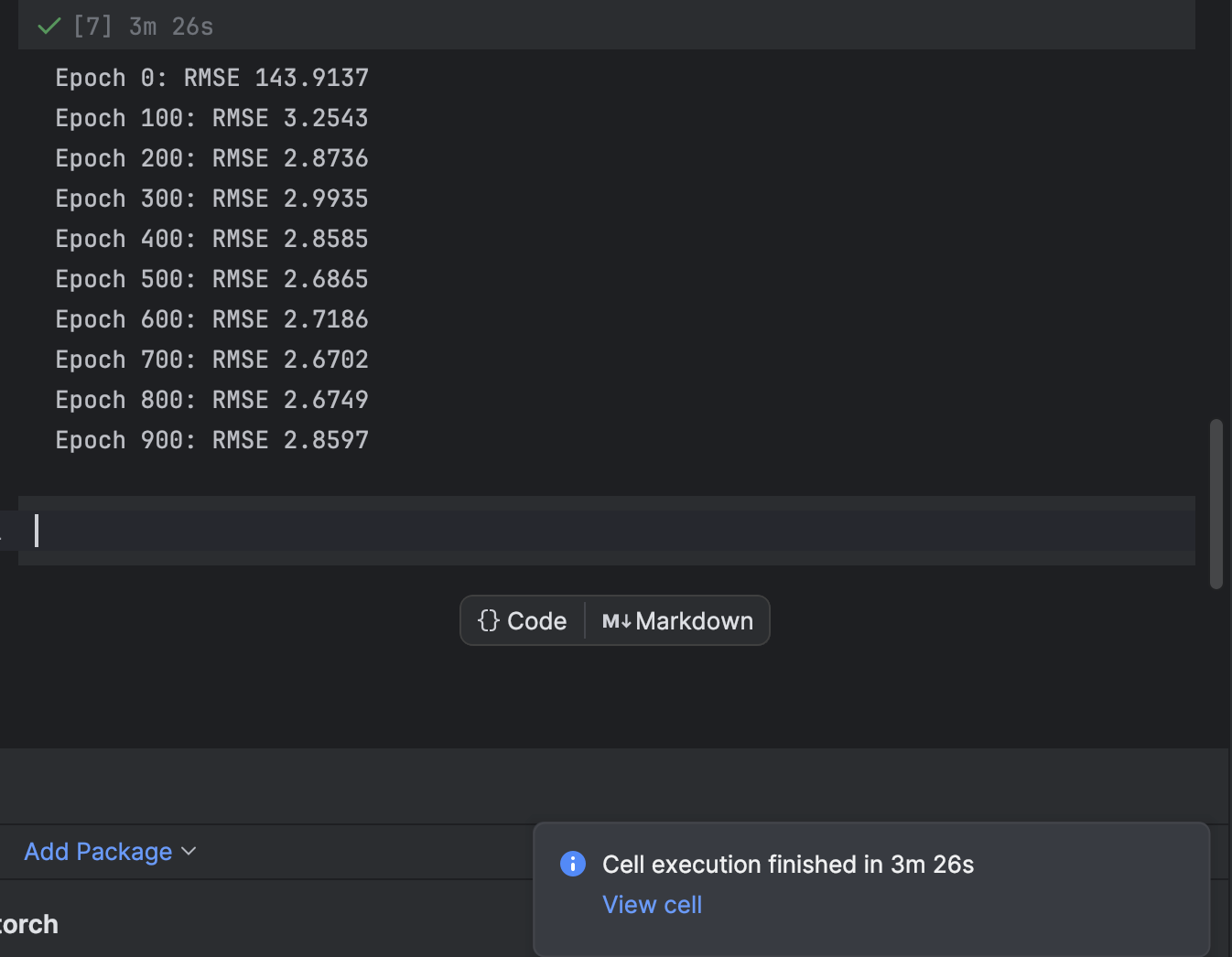
PyCharm では、実行に時間を要するセルから残り時間とセルへのショートカットが含まれる通知が出力されます。 これは機械学習モデル、特にディープラーニングモデルを Jupyter ノートブックでトレーニングする場合に非常に便利です。
5. 予測をプロットして誤差を見つける
次に、予測を作成し、実際の時系列と一緒にプロットします。 実際の時系列に一致させるには、2 次元の np 系列を作成する必要があることに注意してください。 実際の時系列は青、予測された時系列は赤で表示されます。
import matplotlib.pyplot as plt
with torch.no_grad():
pred_series = np.ones_like(timeseries) * np.nan
pred_series[lookback:] = model(X)[:, -1, :]
plt.plot(timeseries, c='b')
plt.plot(pred_series, c='r')
plt.show()

よく観察すると、予測と実際の値が完全に一致しないことが分かりますが、 ほとんどの予測は良好だと言えます。
誤差を詳しく検査するため、誤差系列を作成し、対話型テーブルを使用して観察することができます。 今回は絶対誤差を使用しましょう。
error = abs(timeseries-pred_series) error
設定を使用して絶対誤差の値を x 軸、値のカウントを y 軸としてヒストグラムを作成します。
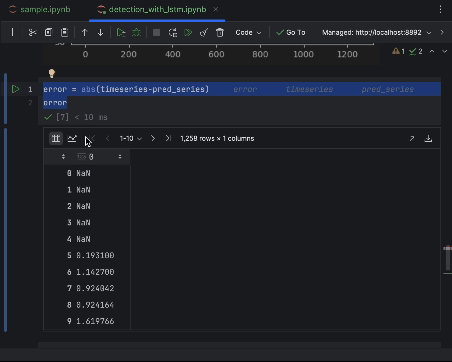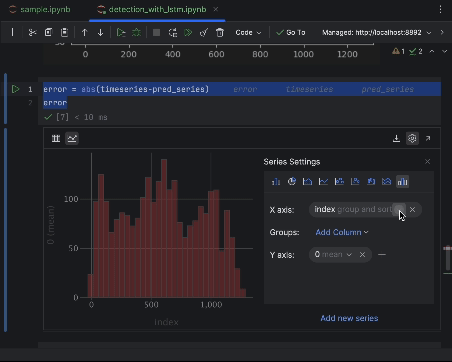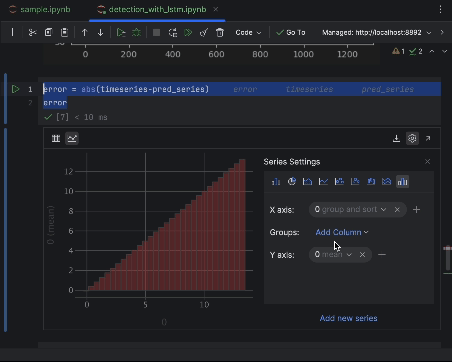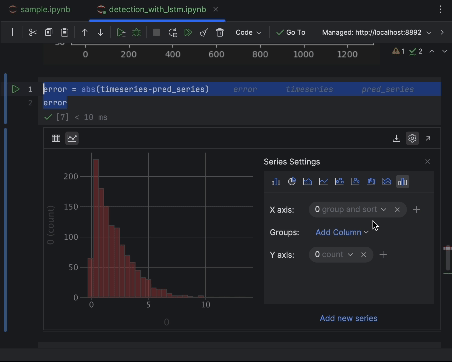
6. 異常のしきい値を決定して可視化する
ほとんどのポイントに 6 未満の絶対誤差があるため、それを異常のしきい値として設定することができます。 養蜂箱の異常で行ったように、異常なデータポイントをグラフにプロットできます。
threshold = 6
error_series = pd.Series(error.flatten())
price_series = pd.Series(timeseries.flatten())
anomalies_filter = error_series.apply(lambda x: True if x > threshold else False)
anomalies = price_series[anomalies_filter]
plt.figure(figsize=(14, 8))
plt.scatter(x=anomalies.index, y=anomalies, color="red", label="anomalies")
plt.plot(df.index, timeseries, color='blue')
plt.title('Closing price')
plt.xlabel('Days')
plt.ylabel('Price')
plt.legend()
plt.show()

まとめ
時系列データは、ビジネスや科学研究などの多数の用途で使用されるデータの共通形式です。 時系列データの連続的な性質により、データ内の異常を判定するための特殊な手法とアルゴリズムが使用されています。 このブログ記事では、STL 分解を使って季節性とトレンドを除去することで異常を発見する方法を紹介しました。 また、ディープラーニングと LSTM モデルを使用して予測された推定値と実際のデータを比較することで異常を判断する方法も紹介しました。
PyCharm による異常の検知
PyCharm Professional で Jupyter プロジェクトを使用すると、多数のデータファイルとノートブックを使って異常検知プロジェクトを簡単に準備することができます。 PyCharm ではグラフ出力を生成して異常を検査することが可能で、プロットにも非常に簡単にアクセスできます。 自動補完による提案などのその他の機能を使用すれば、Scikit-learn モデルと Matplotlib プロットのすべての設定も簡単に操作できます。
PyCharm を使用してデータサイエンスプロジェクトをレベルアップしましょう。また、データサイエンスワークフローの合理化に役立つデータサイエンス機能をご覧ください。
オリジナル(英語)ブログ投稿記事の作者:

Subscribe to PyCharm Blog updates





