

Limpieza de datos en la ciencia de datos

En esta serie de artículos del blog de Ciencia de datos, hemos hablado de dónde obtener datos y cómo explorar esos datos utilizando pandas, pero aunque esos datos son excelentes para el aprendizaje, no son similares a lo que denominaremos datos del mundo real. Los datos para el aprendizaje a menudo ya se han limpiado y pulido para que pueda aprender rápidamente sin necesidad de aventurarse al mundo de la limpieza de datos, pero los datos del mundo real tienen problemas y están desordenados. Los datos del mundo real requieren una limpieza previa para poder ofrecernos datos útiles, y ese es el tema de este artículo del blog.
Los problemas con los datos pueden provenir del comportamiento de los propios datos, de la forma en que se recopilaron o incluso de la forma en que se introdujeron. Pueden ocurrir errores y descuidos en cada etapa del recorrido.
Aquí hablamos específicamente de limpieza de datos y no de transformación de datos. La limpieza de datos garantiza que las conclusiones que extraiga de sus datos puedan generalizarse a la población que defina. Por el contrario, la transformación de datos implica tareas como la conversión de formatos de datos, la normalización de datos y la agregación de datos.
¿Por qué es importante la limpieza de datos?
Lo primero que debemos entender sobre los conjuntos de datos es lo que representan. La mayoría de los conjuntos de datos son una muestra que representa a una población más amplia y, al trabajar con esta muestra, podrá extrapolar (o generalizar) sus conclusiones a esta población. Por ejemplo, hemos utilizado un conjunto de datos en los dos artículos anteriores del blog. Este conjunto de datos trata a grandes rasgos sobre la venta de casas, pero solo cubre una pequeña zona geográfica, un periodo de tiempo pequeño y, potencialmente, no todas las casas de esa zona y ese periodo; es una muestra de una población mayor.
Sus datos deben ser una muestra representativa de la población en general; por ejemplo, todas las ventas de viviendas en esa zona durante un periodo definido. Para asegurarnos de que nuestros datos son una muestra representativa de la población en general, primero debemos definir los límites de nuestra población.
Como podrá imaginar, suele resultar poco práctico trabajar con toda la población, salvo quizá con los datos del censo, por lo que deberá decidir dónde establecer los límites. Estos límites pueden ser geográficos, demográficos, temporales, de acción (como los transaccionales) o específicos del sector. Existen numerosas formas de definir su población, pero para generalizar sus datos de forma fiable, debe definirla antes de limpiar los datos.
En resumen, si planea utilizar sus datos para cualquier tipo de análisis o aprendizaje automático, debe dedicar tiempo a limpiarlos para asegurarse de poder confiar en sus conclusiones y generalizarlas al mundo real. La limpieza de sus datos da como resultado análisis más precisos y, cuando se trata de aprendizaje automático, también mejoras en el rendimiento.
Si no limpia sus datos, se arriesga a problemas como no poder generalizar sus conclusiones a la población en general de forma fiable, estadísticas de resumen inexactas y visualizaciones incorrectas. Si utiliza sus datos para entrenar modelos de aprendizaje automático, esto también puede dar lugar a errores y predicciones inexactas.
Pruebe PyCharm Professional gratis
Ejemplos de limpieza de datos
Vamos a echar un vistazo a cinco tareas que puede utilizar para limpiar sus datos. No se trata de una lista exhaustiva, pero es un buen punto de partida cuando lleguen a sus manos datos del mundo real.
Deduplicación de datos
Los duplicados son un problema, porque pueden distorsionar sus datos. Imagine que está trazando un histograma en el que utiliza la frecuencia de los precios de venta. Si tiene duplicados del mismo valor, obtendrá un histograma que tendrá un patrón inexacto a causa de los precios que están duplicados.
Como nota al margen, cuando hablamos de que la duplicación es un problema en los conjuntos de datos, nos referimos a la duplicación de filas enteras, cada una de las cuales es una única observación. Habrá valores duplicados en las columnas, y eso es lo que esperamos. Solo estamos hablando de observaciones duplicadas.
Afortunadamente para nosotros, existe un método pandas para detectar si hay duplicados en nuestros datos. Podemos utilizar el chat de JetBrains AI si necesitamos un recordatorio con una petición como:
Code to identify duplicate rows
Este sería el código resultante:
duplicate_rows = df[df.duplicated()] duplicate_rows
Este código asume que su DataFrame se llama df, así que asegúrese de cambiarlo por el nombre de su DataFrame si no es así.
No hay ningún dato duplicado en el conjunto de datos de Ames Housing que hemos estado utilizando, pero si le apetece probarlo, eche un vistazo al conjunto de datos de la base de datos de comercio de fauna silvestre CITES y vea si puede encontrar los duplicados utilizando el método pandas anterior.
Una vez que haya identificado los duplicados en su conjunto de datos, debe eliminarlos para evitar distorsionar los resultados. Para ello, puede obtener el código con JetBrains AI de nuevo con una petición como:
Code to drop duplicates from my dataframe
El código resultante elimina los duplicados, restablece el índice de su DataFrame y, a continuación, lo muestra como un nuevo DataFrame llamado df_cleaned:
df_cleaned = df.drop_duplicates() df_cleaned.reset_index(drop=True, inplace=True) df_cleaned
Hay otras funciones de pandas que puede utilizar para una gestión de duplicados más avanzada, pero esta es suficiente para empezar a deduplicar su conjunto de datos.
Tratamiento de valores inverosímiles
Se pueden obtener valores inverosímiles cuando los datos se introducen incorrectamente o algo ha ido mal durante el proceso de recopilación de datos. Para nuestro conjunto de datos Ames Housing, un valor inverosímil podría ser un SalePrice negativo, o un valor numérico en Roof Style.
La detección de valores inverosímiles en su conjunto de datos se basa en un enfoque amplio que incluye examinar sus estadísticas resumidas, comprobar las reglas de validación de datos definidas por el recopilador para cada columna y anotar cualquier punto de datos que quede fuera de esta validación, así como usar visualizaciones para detectar patrones y cualquier cosa que parezca ser una anomalía.
Es importante ocuparse de los valores inverosímiles, ya que pueden añadir ruido y causar problemas en su análisis. Sin embargo, la forma de tratarlos está en cierto modo abierta a la interpretación. Si no tiene muchos valores inverosímiles en relación con el tamaño de su conjunto de datos, puede eliminar los registros que los contengan. Por ejemplo, si ha identificado un valor inverosímil en la fila 214 de su conjunto de datos, puede utilizar la función drop de pandas para eliminar esa fila de su conjunto de datos.
Una vez más, podemos hacer que JetBrains AI genere el código que necesitamos con una petición como:
Code that drops index 214 from #df_cleaned
Tenga en cuenta que en los notebooks de Jupyter de PyCharm podemos poner el signo # antes de una palabra para indicar al JetBrains AI Assistant que estoamos proporcionando contexto adicional y, en este caso, que el DataFrame se llama df_cleaned.
El código resultante eliminará esa observación de su DataFrame, restablecerá el índice y lo mostrará:
df_cleaned = df_cleaned.drop(index=214) df_cleaned.reset_index(drop=True, inplace=True) df_cleaned
Otra estrategia popular para tratar los valores inverosímiles es imputarlos, lo que significa que se sustituye el valor por otro diferente y verosímil basado en una estrategia definida. Una de las estrategias más comunes es utilizar el valor mediano en lugar del valor inverosímil. Dado que la mediana no se ve afectada por los valores atípicos, los científicos de datos suelen elegirla para este fin, pero igualmente, la media o el valor de la moda de sus datos podrían ser más apropiados en algunas situaciones.
Como alternativa, si tiene conocimientos sobre el conjunto de datos y sobre cómo se recopilaron, puede sustituir el valor inverosímil por otro que tenga más sentido. Si participa en el proceso de recopilación de datos o lo conoce, esta opción puede ser para usted.
La forma en que decida tratar los valores inverosímiles dependerá de su prevalencia en el conjunto de datos, de cómo se hayan recogido los datos y de cómo pretenda definir su población, así como de otros factores como sus conocimientos del ámbito.
Formateo de datos
A menudo puede detectar problemas de formato con sus estadísticas de resumen o con las primeras visualizaciones que realice para hacerse una idea de la forma de sus datos. Algunos ejemplos de formato incoherente son los valores numéricos que no se definen todos con el mismo decimal o las variaciones ortográficas, como «primero» y «1º». Un formateo incorrecto de los datos también puede afectar a la huella de memoria de sus datos.
Cuando detecte problemas de formateo en su conjunto de datos, deberá estandarizar los valores. Dependiendo del problema al que se enfrente, esto implica normalmente definir su propia norma y aplicar el cambio. De nuevo, la biblioteca pandas tiene algunas funciones útiles aquí como la de redondear. Si quisiera redondear la columna SalePrice a 2 decimales, podríamos pedir el código a JetBrains AI:
Code to round #SalePrice to two decimal places
El código resultante realizará el redondeo y luego imprimirá las 10 primeras filas para que pueda comprobarlo:
df_cleaned['SalePrice'] = df_cleaned['SalePrice].round(2) df_cleaned.head()
Otro ejemplo sería el de una ortografía incoherente: por ejemplo, una columna HouseStyle que tenga tanto “1Story” como “OneStory”, y usted sepa que significan lo mismo. Puede utilizar la siguiente petición para obtener el código correspondiente:
Code to change all instances of #OneStory to #1Story in #HouseStyle
El código resultante hace exactamente eso: sustituye todas las instancias de «OneStory» por «1Story»:
df_cleaned[HouseStyle'] = df_cleaned['HouseStyle'].replace('OneStory', '1Story')
Abordar los valores atípicos
Los valores atípicos son muy comunes en los conjuntos de datos, pero la forma de abordarlos, si es que se abordan, depende mucho del contexto. Una de las formas más sencillas de detectar valores atípicos es con un diagrama de caja, que utiliza las bibliotecas seaborn y matplotlib. Ya hablé de los diagramas de caja en mi anterior artículo del blog sobre la exploración de datos con pandas, por si necesita un repaso rápido.
Nos fijaremos en SalePrice en nuestro conjunto de datos de Ames Housing para este diagrama de caja. De nuevo, utilizaré JetBrains IA para que genere el código por mí con una petición como la siguiente:
Code to create a box plot of #SalePrice
Aquí está el código resultante que debemos ejecutar:
import seaborn as sns
import matplotlib.pyplot as plt
# Create a box plot for SalePrice
plt.figure(figsize=(10, 6))
sns.boxplot(x=df_cleaned['SalePrice'])
plt.title('Box Plot of SalePrice')
plt.xlabel('SalePrice')
plt.show()
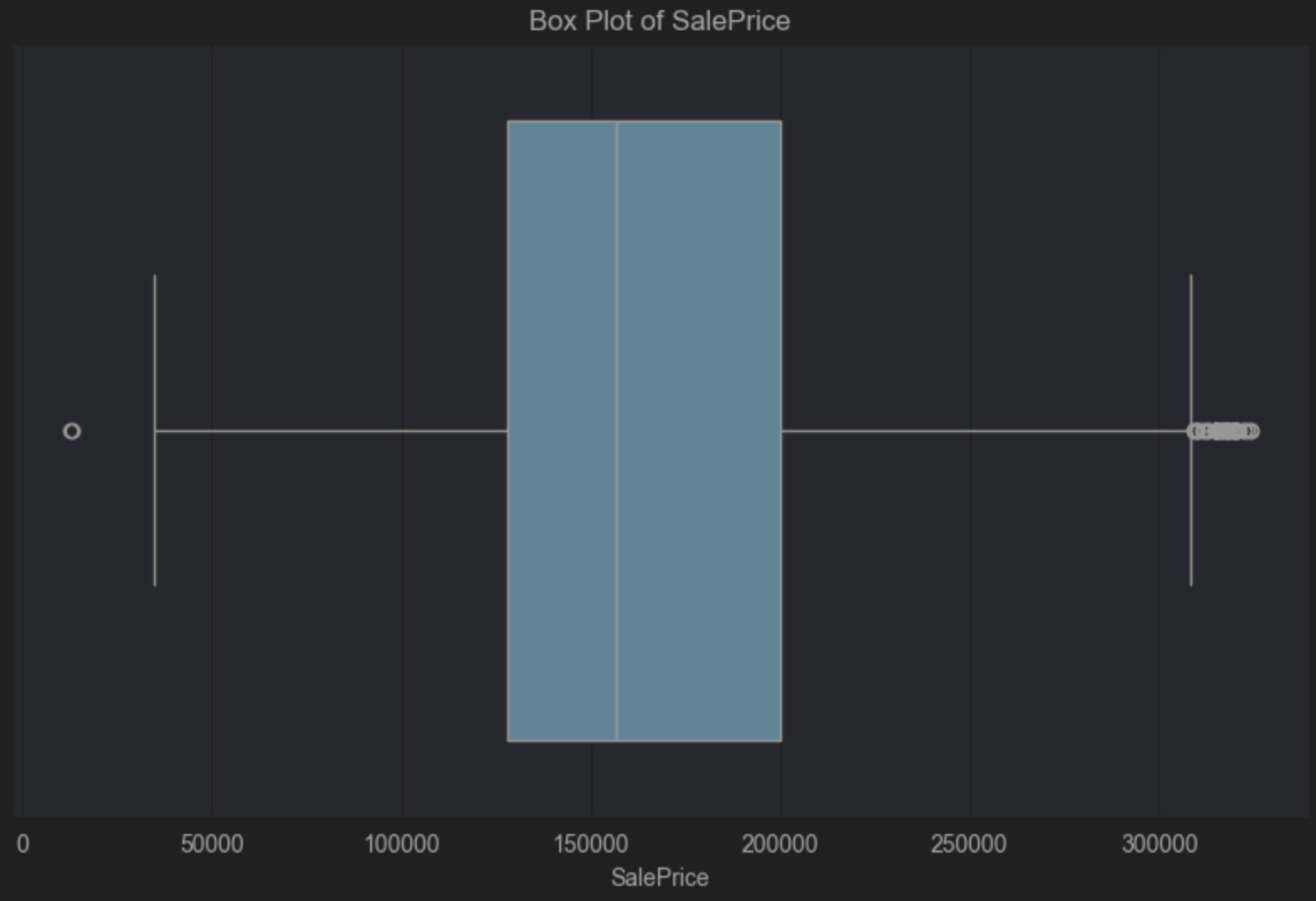
El diagrama de caja nos indica que tenemos un sesgo positivo porque la línea mediana vertical dentro de la caja azul está a la izquierda del centro. Un sesgo positivo nos dice que tenemos más precios de la vivienda en el extremo más barato de la escala, lo que no es sorprendente. El diagrama de caja también nos indica visualmente que tenemos muchos valores atípicos en el lado derecho. Se trata de un pequeño número de casas mucho más caras que el precio de la mediana.

Puede aceptar estos valores atípicos ya que es bastante habitual que un pequeño número de casas tenga un precio superior al de la mayoría. Sin embargo, todo esto depende de la población a la que quiera poder generalizar y de las conclusiones que desee extraer de sus datos. Establecer límites claros en torno a lo que forma parte de su población y lo que no, le permitirá tomar una decisión informada sobre si los valores atípicos en sus datos van a suponer un problema.
Por ejemplo, si su población está formada por personas que no van a comprar mansiones caras, tal vez pueda eliminar estos valores atípicos. Si, por el contrario, la demografía de su población incluye a aquellos de los que cabe esperar razonablemente que compren estas casas caras, quizá quiera mantenerlas, ya que son relevantes para su población.
He hablado aquí de los diagramas de caja como formas de detectar valores atípicos, pero otras opciones como los diagramas de dispersión y los histogramas pueden mostrarle rápidamente si tiene valores atípicos en sus datos, para que pueda tomar una decisión informada sobre si necesita hacer algo al respecto.
El tratamiento de los valores atípicos suele dividirse en dos categorías: eliminarlos o utilizar estadísticas de resumen menos propensas a los valores atípicos. En primer lugar, necesitamos saber exactamente de qué filas se trata.
Hasta ahora, solo hemos hablado de cómo identificarlos visualmente. Hay diferentes formas de determinar qué observaciones son y no son valores atípicos. Un enfoque habitual es utilizar un método denominado puntuación Z modificada. Antes de ver cómo y por qué se modifica, la puntuación Z se define de la siguiente manera:
Puntuación Z = (valor del punto de datos – media) / desviación típica
Así pues, la razón por la que modificamos la puntuación Z para detectar valores atípicos es que tanto la media como la desviación típica son propensas a la influencia de valores atípicos según cómo se calculan. La puntuación Z modificada se define como:
Puntuación Z modificada = (valor del punto de datos – mediana) / mediana de las desviaciones absolutas
Como aprendimos cuando hablamos de las estadísticas de resumen, la mediana no se ve afectada por los valores atípicos. La mediana de las desviaciones absolutas es el valor de la mediana de las desviaciones absolutas del conjunto de datos con respecto a la mediana. Por ejemplo, si su conjunto de datos contiene estos valores:
1, 2, 2, 2, 3, 3, 3, 5,9
Entonces su mediana es 3 como valor en el centro del conjunto de datos. Las desviaciones de su valor de mediana de 3 son las siguientes en el orden presentado anteriormente:
2, 1, 1, 1, 0, 0, 0, 2, 5
Si las ordenamos en orden ascendente obtenemos lo siguiente:
0, 0, 0, 1, 1, 1, 2, 2, 5
Lo que significa que la mediana de las desviaciones absolutas en este ejemplo sería 1.
¿Cómo calculamos la puntuación Z modificada de nuestro conjunto de datos para SalePrice? Pidámosle a JetBrains AI lo siguiente:
Given:
Modified Z-score = (data point value – median) / median absolute deviation
Calculate the Modified Z-score for #SalePrice
El resultado es este código:
import pandas as pd from scipy.stats import median_abs_deviation # Assuming 'data' is your DataFrame and it contains the 'SalePrice' column # Calculate the median for the SalePrice column median_sale_price = data['SalePrice'].median() # Calculate the Median Absolute Deviation (MAD) for the SalePrice column mad_sale_price = median_abs_deviation(data['SalePrice'], scale='normal') # Calculate the Modified Z-scores for the SalePrice column data['Modified_Z_Score'] = (data['SalePrice'] - median_sale_price) / mad_sale_price # Display the first few rows with the Modified Z-scores print(data[['SalePrice', 'Modified_Z_Score']].head())
Cuando instalamos los paquetes necesarios y ejecutamos este código, podemos ver que ya hemos recorrido parte del camino, pero ahora tenemos que decidir qué es un valor atípico para nuestro SalePrice basándonos en la puntuación Z modificada. La concepción general aquí es que un valor atípico es cualquier valor >=3 o <=-3. Sin embargo, conviene señalar que, como la mayoría de las decisiones estadísticas, puede y debe adaptarse a su conjunto de datos. <=-3 however, it’s worth noting that like most statistical decisions, it can and should be tailored to your dataset.
Pasemos otra petición a JetBrains AI para que podamos adaptar aún más nuestro resultado:
Just list those that have a #Modified_Z_Score of 3 or above or -3 or below
Voy a tomar este fragmento de código y a sustituirlo por las filas pertinentes de arriba:
# Filter the rows where the Modified Z-score is 3 or above, or -3 or below outliers = data[(data['Modified_Z_Score'] >= 3) | (data['Modified_Z_Score'] <= -3)] # Print all the filtered rows, showing their index and SalePrice outliers = (outliers[['SalePrice', 'Modified_Z_Score']]) outliers
He modificado este código para guardar los valores atípicos en un nuevo DataFrame llamado valores atípicos e imprimirlos para poder verlos.
Nuestro siguiente paso sería eliminar estos valores atípicos de nuestro DataFrame. Una vez más podemos utilizar JetBrains AI para generar el código con una petición como:
Create a new dataframe without the outliers
data_without_outliers = data.drop(index=outliers.index) # Display the new DataFrame without outliers print(data_without_outliers)
Nuestro nuevo DataFrame, data_without_outliers, excluye aquellos valores en los que la variable SalePrice se considera un valor atípico.
Podemos actualizar nuestro código de diagrama de caja para ver el nuevo DataFrame. Sigue mostrando nuestro sesgo positivo como cabría esperar, pero se han eliminado los valores considerados atípicos:
import seaborn as sns
import matplotlib.pyplot as plt
# Create a box plot for SalePrice
plt.figure(figsize=(10, 6))
sns.boxplot(x=data_without_outliers['SalePrice'])
plt.title('Box Plot of SalePrice')
plt.xlabel('SalePrice')
plt.show()
Antes de terminar aquí, echemos un vistazo a cuántas observaciones se han eliminado de nuestro DataFrame como porcentaje porque las consideramos valores atípicos en función de SalePrice.
Podemos utilizar una petición como esta:
Calculate the percentage of observations removed between #data and #data_without_outliers
# Calculate the number of observations in the original and filtered DataFrames
original_count = len(data)
filtered_count = len(data_without_outliers)
# Calculate the number of removed observations
removed_count = original_count - filtered_count
# Calculate the percentage of observations removed
percentage_removed = (removed_count / original_count) * 100
# Display the percentage
print(f"Percentage of observations removed: {percentage_removed:.2f}%")
PyCharm nos indica que se han eliminado el 5,67 % de las observaciones.
Como he dicho antes, si mantiene los valores atípicos, considere la posibilidad de utilizar valores de resumen menos propensos a verse afectados por los valores atípicos, como la mediana y el rango intercuartílico. Puede plantearse utilizar estas medidas para sacar conclusiones cuando trabaje con conjuntos de datos que sabe que contienen valores atípicos que no ha eliminado porque son relevantes para la población que ha definido y las conclusiones que desea extraer.
Valores omitidos
La forma más rápida de detectar los valores que faltan en un conjunto de datos es con sus estadísticas de resumen. Como recordatorio, en su DataFrame, haga clic en Show Column Statistics en el lado derecho y luego seleccione Compact. Los valores que faltan en las columnas se muestran en rojo, como puede ver aquí para «Lot Frontage» en nuestro conjunto de datos de Ames Housing:
Hay tres tipos de omisión que debemos tener en cuenta para nuestros datos:
- Omisión completa al azar
- Omisión al azar
- Omisión no al azar
Omisión completa al azar
Omisión completa al azar significa que el dato ha desaparecido totalmente por casualidad y que el hecho de que falte no tiene relación con otras variables del conjunto de datos. Esto puede ocurrir cuando alguien olvida responder a una pregunta de la encuesta, por ejemplo.
Los datos omitidos completamente al azar son raros, pero también son de los más fáciles de tratar. Si tiene un número relativamente pequeño de observaciones omitidas completamente al azar, el enfoque más común es eliminar esas observaciones, porque hacerlo no debería afectar a la integridad de su conjunto de datos y, por tanto, a las conclusiones que espera extraer.
Omisión al azar
Omisión al azar no parece tener un patrón, pero tiene un patrón subyacente que podemos explicar a través de otras variables que hemos medido. Por ejemplo, alguien no respondió a una pregunta de la encuesta debido a la forma en que se obtuvieron los datos.
Si volvemos a considerar nuestro conjunto de datos de Ames Housing, quizá la variable «Lot Frontage» (fachada de la parcela) falte con más frecuencia en las casas que venden ciertas agencias inmobiliarias. En ese caso, esta omisión podría deberse a prácticas incoherentes de introducción de datos por parte de algunas agencias. Si es cierto, el hecho de que falten datos de «Lot Frontage» está relacionado con la forma en que la agencia que vendió la propiedad recopiló los datos, que son una característica observada, no la fachada de la parcela en sí.
Cuando le falten datos al azar, querrá entender por qué faltan esos datos, lo que a menudo implica indagar en cómo se recopilaron los datos. Una vez que entienda por qué faltan los datos, podrá elegir qué hacer. Uno de los enfoques más comunes para hacer frente a los valores omitidos al azar es imputar los valores. Ya hemos hablado de esto para los valores inverosímiles, pero también es una estrategia válida para los valores que faltan. Existen varias opciones entre las que podría elegir en función de la población definida y de las conclusiones que desee extraer, incluido el uso de variables correlacionadas como el tamaño de la casa, el año de construcción y el precio de venta en este ejemplo. Si comprende el patrón que hay detrás de los datos que faltan, a menudo puede utilizar información contextual para imputar los valores, lo que garantiza que se conserven las relaciones entre los datos de su conjunto de datos.
Omisión no al azar
Por último, la omisión no al azar se da cuando la probabilidad de que falten datos está relacionada con datos no observados. Eso significa que la omisión depende de los datos no observados.
Por última vez, volvamos a nuestro conjunto de datos de Ames Housing y al hecho de que nos faltan datos en «Lot Frontage» (fachada de la parcela). Una situación de datos omitidos no al azar es cuando los vendedores deciden deliberadamente no informar del dato sobre la fachada de la parcela si consideran que es pequeña y, por tanto, informar al respecto podría reducir el precio de venta de su casa. Si la probabilidad de que falten datos de «Lot Frontage» depende del tamaño de la propia fachada (que no se observa), es menos probable que se notifiquen las fachadas de parcelas más pequeñas, lo que significa que la omisión de datos está directamente relacionada con el valor que falta.
Visualizar la omisión
Siempre que falten datos, hay que comprobar si existe un patrón. Si tiene un patrón, entonces tiene un problema que probablemente deberá resolver antes de poder generalizar sus datos.
Una de las formas más sencillas de buscar patrones es con las visualizaciones de mapas de calor. Antes de entrar en el código, vamos a excluir las variables que no tengan ninguna omisión. Podemos pedir a JetBrains AI este código:
Code to create a new dataframe that contains only columns with missingness
Este es nuestro código:
# Identify columns with any missing values columns_with_missing = data.columns[data.isnull().any()] # Create a new DataFrame with only columns that have missing values data_with_missingness = data[columns_with_missing] # Display the new DataFrame print(data_with_missingness)
Antes de ejecutar este código, cambie la línea final para que podamos disfrutar del bonito diseño de DataFrames de PyCharm:
data_with_missingness
Ahora es el momento de crear un mapa de calor; de nuevo le pediremos a JetBrains AI un código como este:
Create a heatmap of #data_with_missingness that is transposed
Este sería el código resultante:
import seaborn as sns
import matplotlib.pyplot as plt
# Transpose the data_with_missingness DataFrame
transposed_data = data_with_missingness.T
# Create a heatmap to visualize missingness
plt.figure(figsize=(12, 8))
sns.heatmap(transposed_data.isnull(), cbar=False, yticklabels=True)
plt.title('Missing Data Heatmap (Transposed)')
plt.xlabel('Instances')
plt.ylabel('Features')
plt.tight_layout()
plt.show()
Tenga en cuenta que he eliminado cmap=’viridis’ de los argumentos del mapa de calor, ya que me resulta difícil visualizarlo.

Este mapa de calor sugiere que podría haber un patrón de omisión porque faltan las mismas variables en varias filas. En un grupo, podemos ver que Bsmt Qual, Bsmt Cond, Bsmt Exposure, BsmtFin Type 1 y Bsmt Fin Type 2 faltan en las mismas observaciones. En otro grupo, podemos ver que Garage Type, Garage Yr Bit, Garage Finish, Garage Qual y Garage Cond faltan en las mismas observaciones.
Todas estas variables están relacionadas con sótanos y garajes, pero hay otras variables relacionadas con garajes o sótanos que no faltan. Una posible explicación es que se formularon preguntas diferentes sobre garajes y sótanos en las distintas agencias inmobiliarias cuando se recopilaron los datos, y no todas registraron tantos detalles como los que figuran en el conjunto de datos. Estos escenarios son comunes con datos que no recoge usted mismo, y puede explorar cómo se recopilaron los datos si necesita saber más sobre la falta de datos en su conjunto de datos.
Buenas prácticas para la limpieza de datos
Como ya he mencionado, la definición de su población ocupa un lugar destacado en la lista de las mejores prácticas para la limpieza de datos. Sepa qué desea conseguir y cómo quiere generalizar sus datos antes de empezar a limpiarlos.
Debe asegurarse de que todos sus métodos son reproducibles, porque la reproducibilidad también requiere datos limpios. Las situaciones que no son reproducibles pueden causar un impacto significativo más adelante. Por este motivo, le recomiendo que mantenga sus notebooks de Jupyter ordenados y secuenciales, y que aproveche las funciones de Markdown para documentar su toma de decisiones en cada paso, especialmente con la limpieza.
Al limpiar los datos, debe trabajar de forma incremental, modificando el DataFrame en lugar del archivo CSV o la base de datos originales, y asegurándose de hacerlo todo con un código reproducible y bien documentado.
Resumen
La limpieza de datos es un gran tema y puede plantear muchos retos. Cuanto mayor sea el conjunto de datos, más difícil será el proceso de limpieza. Tendrá que tener en cuenta a su población para generalizar sus conclusiones de forma más amplia y, al mismo tiempo, equilibrar las compensaciones entre eliminar e imputar los valores que faltan y comprender por qué faltan esos datos en primer lugar.
Puede considerarse a sí mismo como la voz de los datos. Usted conoce el camino que han recorrido los datos y cómo ha mantenido la integridad de estos en todas las etapas. Usted es la persona más indicada para documentar ese viaje y compartirlo con los demás.
Pruebe PyCharm Professional gratis
Artículo original en inglés de:

Subscribe to PyCharm Blog updates





